9. nodaļa. Korelācijas analīze
9.1 Teorētiskais pamatojums
Vēl jāuzraksta
9.2 Korelācijas analīze programmā R
9.2.1 Grafiskā pārbaude
Pirms veikt analītiski korelācijas analīzi vienmēr ir ieteicams savus datus apskatīties grafiski, tādējādi ir iespējams pārliecināties vai datos nav kādas ekstrēmas vērtības, kā arī var gūt sākotnējo priekštatu par to, kuras pazīmes ir savā starpā saistītas.
Piemēram izmantosim datu failu smiltaji.txt, kas satur informāciju par augsnes pH, atsegtas smilts un sūnu segumu parauglaukumos, kā arī šajos parauglaukumos konstatēto vaskulāro augu sugu skaitu.
smiltaji<-read.table(file="smiltaji.txt",header=TRUE,sep="\t",dec=".")Tā kā šajā datu tabulā visās kolonnās ir skaitļi, tad ir iespējams veidot visām kolonnām uzreiz. Tam noder funkcija pairs(), kas izveido izkliedes grafiku jebkurām divām no datu tabulas.
pairs(smiltaji)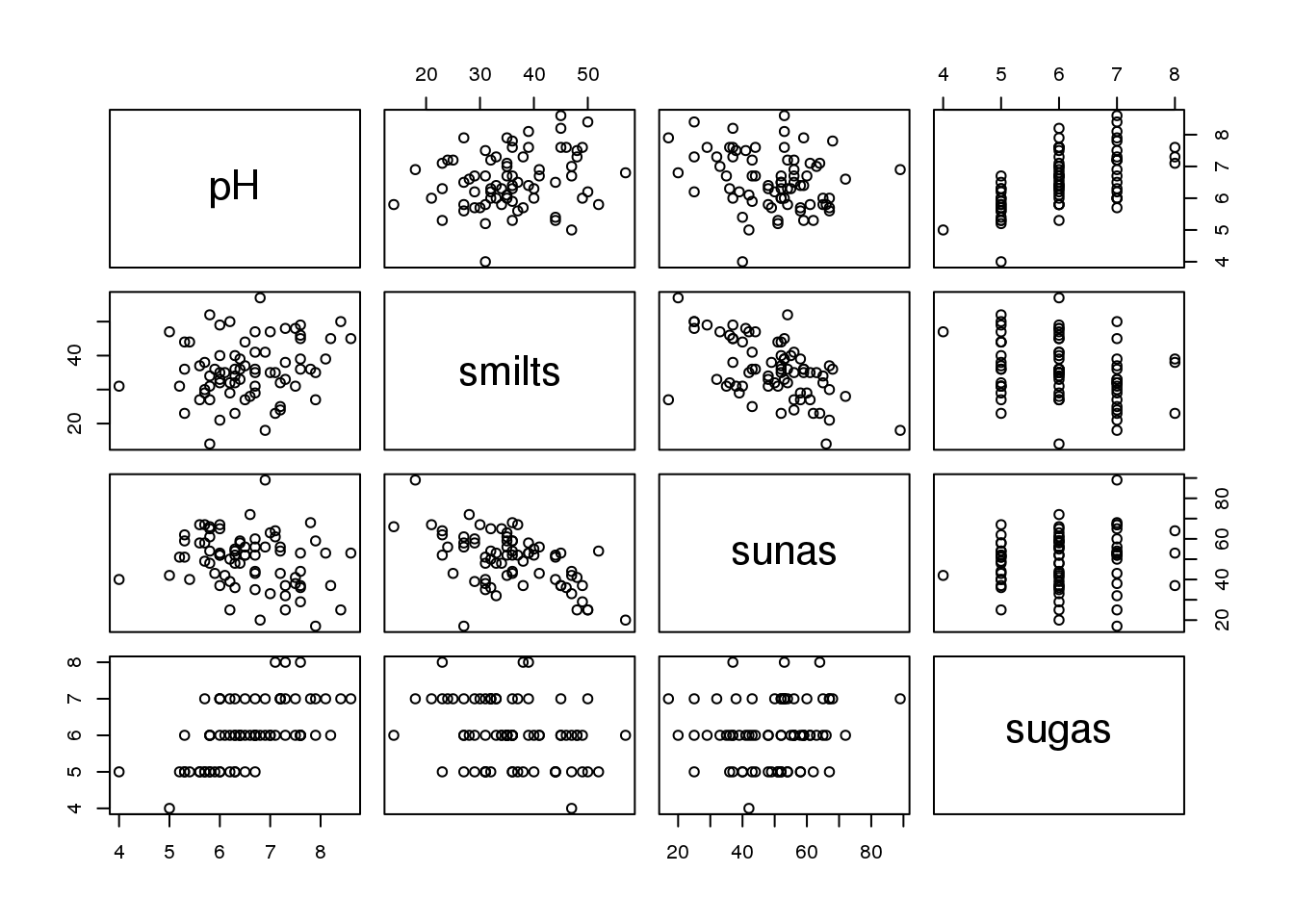
Figure 9.1: Izkliedes grafiki starp visām smiltāju datu tabulas kolonnām
No attēla (9.1 attēls) redzams, ka ir saistība starp smilts un sūnu segumiem (negatīva), kā arī iespējams starp smilts segumu un augsnes pH. Attiecībā uz sugus skaitu veidojas dīvainas formas attēls, jo šim mainīgajam ir tikai piecas iespējamās vērtības.
Nākamais solis, ja tas jau nav izdarīts iepriekš, ir pārbaudīt vai dati atbilst normālajam sadalījumam. Šoreiz to pārbaudīsim grafiski katrai no kolonnām izveidojot QQ grafiku. Izmantojot funkciju for(), panākts, ka četras reizes nav jāraksta funkcija grafika zīmēšanai.
par(mfrow=c(2,2))
library(car)
for(i in 1:4){
qqPlot(smiltaji[,i],main=names(smiltaji)[i])
}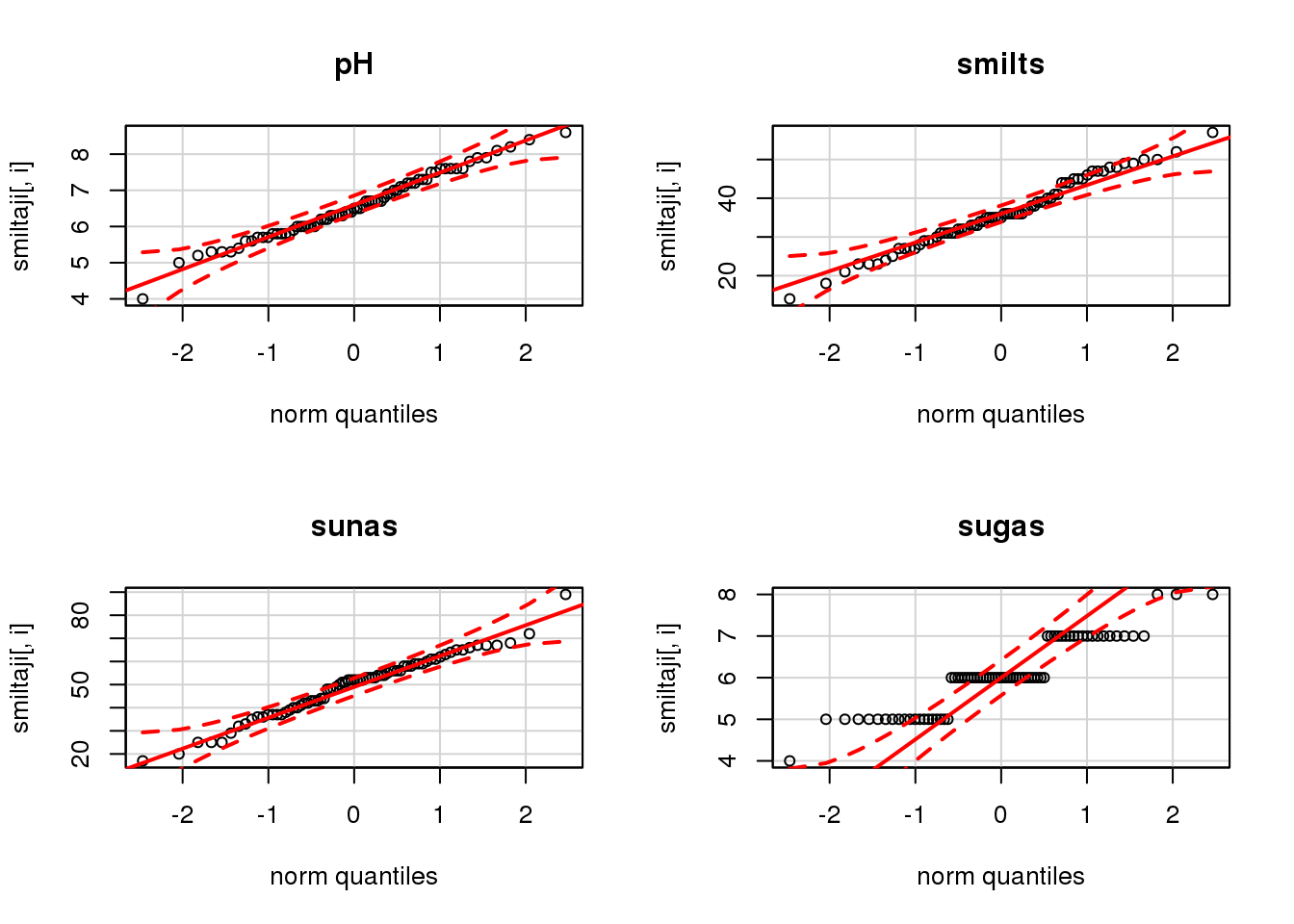
Figure 9.2: QQ grafiki smiltāju tabulas mainīgajiem
9.2 attēls skaidri parāda, ka mainīgais sugu skaits neatbilst normālajam sadalījumam, bet pārējiem trim mainīgajiem varam pieņemt atbilstību normālajam sadalījumam.
9.2.2 Pīrsona korelācijas analīze
Pamatfunkcijas korelācijas analīzes veikšanai programmā R ir cor() un cor.test(). Funkcijā cor() kā mainīgo var likt gan datu tabulu ar vairākām kolonnām, gan divas datu tabulas, ja nepieciešams noskaidrot korelāciju starp abu tabulu kolonnām. Rezultātā parādās matrice, kas satur korelācijas koeficientus starp jebkurām divām analizētajām kolonnām. Pēc noklusējuma funkcija aprēķina Pīrsona korelācijas koeficientu.
Piemērā ar tabulu smiltaji aprēķināti korelācijas koeficienti starp pirmajām trim kolonnām, jo ceturtās kolonnas dati neatbilda normālajam sadalījumam. Iegūtie korelācijas koeficienti ir robežās no -0.558 līdz 0.221 (korelācijas koeficients 1 mainīgajam pašam ar sevi). Diemžēl pēc funkcijas cor() rezultātiem nav iespējams secināt, kuri korelācijas koeficienti ir statistiski būtiski. Lai to izdarītu, ir jāizmanto specializētās tabulas vai arī papildus aprēķinus.
cor(smiltaji[,1:3])## pH smilts sunas
## pH 1.0000000 0.2213315 -0.2517885
## smilts 0.2213315 1.0000000 -0.5576408
## sunas -0.2517885 -0.5576408 1.0000000Ja ir nepieciešams uzreiz aprēķināt gan korelācijas koeficientus, gan novērtēt to būtiskumu vairākam datu kolonnām, var izmantot funkciju rcor.test() no paketes ltm. Rezultātā parādās matrica, kurā augšējā daļā ir korelācijas koeficienti, bet apakšējā daļā ir atbilstošās p-vērtības. Varam secināt, ka statistiski būtiska (pie \(\alpha=0.05\)) korelācija pastāv starp pazīmēm pH un sūnu segums, kā arī smilts un sūnu segums, jo attiecīgi p vērtības ir 0,032 un <0,001. Korelācija starp pH un smilts segumu nav statistiski būtiska, kaut arī p-vērtība ir ļoti tuvu kritiskajai robežai (0,06).
library(ltm)## Loading required package: MASS## Loading required package: msm##
## Attaching package: 'msm'## The following object is masked from 'package:boot':
##
## cav## Loading required package: polycor## Loading required package: mvtnorm## Loading required package: sfsmiscrcor.test(smiltaji[,1:3])##
## pH smilts sunas
## pH ***** 0.221 -0.252
## smilts 0.060 ***** -0.558
## sunas 0.032 <0.001 *****
##
## upper diagonal part contains correlation coefficient estimates
## lower diagonal part contains corresponding p-valuesAr otru pamatfunkciju cor.test() var aprēķināt korelācijas koeficientu tikai starp divām kolonnām vai vektoriem (šajā gadījumā pH un sūnu segumu), toties analīzes rezultātos parādās gan pats korelācijas koeficients, gan arī tā ticamības intervāls, kā arī t-vērtības būtiskuma novērtēšanai un p-vērtība.
cor.test(smiltaji$pH,smiltaji$sunas)##
## Pearson's product-moment correlation
##
## data: smiltaji$pH and smiltaji$sunas
## t = -2.1922, df = 71, p-value = 0.03164
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## -0.45547107 -0.02305682
## sample estimates:
## cor
## -0.2517885Secinājums: starp pazīmēm pH un sūnu segums ir statistiski būtiska korelācija pie būtiskuma līmeņa \(\alpha=0,05\).
9.2.3 Rangu korelācijas analīze
Spirmena un Kendela korelācijas analīzes veikšanai izmanto tās pašas funkcijas, kuras izmanto Pīrsona korelācijas analīzes: cor() un cor.test(). Vienīgās izmaiņas ir papildus arguments method= ar iespējamām vērtībām "spearman" un "kendall". Ja izmanto funkciju cor.test(), tad analīzes rezultātos parādās korelācijas koeficients, rādītājs korelācijas koeficients būtiskuma novērtēšanai un iegūtā p-vērtība.
Piemēram izmantoti dati par sugu skaitu (dati neatbilda normālajam sadalījumam) un smilts segumu parauglaukumos.
cor.test(smiltaji$sugas,smiltaji$smilts,method="spearman")## Warning in cor.test.default(smiltaji$sugas, smiltaji$smilts, method =
## "spearman"): Cannot compute exact p-value with ties##
## Spearman's rank correlation rho
##
## data: smiltaji$sugas and smiltaji$smilts
## S = 83657, p-value = 0.01265
## alternative hypothesis: true rho is not equal to 0
## sample estimates:
## rho
## -0.2905304cor.test(smiltaji$sugas,smiltaji$smilts,method="kendall")##
## Kendall's rank correlation tau
##
## data: smiltaji$sugas and smiltaji$smilts
## z = -2.5457, p-value = 0.0109
## alternative hypothesis: true tau is not equal to 0
## sample estimates:
## tau
## -0.2335632Secinājums: gan ar Spirmena, gan ar Kendela korelācijas metodi starp pazīmēm sugu skaits un smilts segu pastāv statistiski būtiska negatīva korelācija (attiecīgi -0,29 un -0,23), jo iegūtās p-vērtības ir mazākas par noteikto būtiskuma līmeni (attiecīgi 0,013 un 0,011 <0,05).
9.2.4 Autokorelācija
Šai analīzei ir nepieciešama datu rinda, kas satur informāciju par laikā veiktiem novērojumiem (var izmantot arī telpā veiktos novērojumus, ja ievērots to izvietojums). Piemēram derēs fails priedes.txt, kas satur informāciju par priedes gadskārtu platumu simts gadu periodā.
priede<-read.table(file="priede.txt",header=T,sep="\t",dec=".")
str(priede)## 'data.frame': 100 obs. of 1 variable:
## $ gadsk: num 0.89 0.92 0.87 1.39 1.11 0.92 1.16 1.08 1.13 1.71 ...Autokorelācijas aprēķināšanai izmanto funkciju acf(), kurai kā arguments jānorāda kolonna/vektors, kas satur laika rindas datus. Rezultātā automātiski parādās attēls (9.3 attēls), kurā attēlotas autokorelācijas vērtības ar nobīdi līdz 20 vienībām (nobīdi var mainīt ar argumentu lag.max=). Korelācijas koeficients uzskatāms par būtiski, ja tā stabiņš pārsniedz raustīto līniju (uz augšu pozitīvajām vērtībām un uz leju negatīvajām vērtībām). Jāņem vērā, ka pirmais stabiņš attiecas uz nobīdi 0 un šis koeficients vienmēr būs 1.
acf(priede)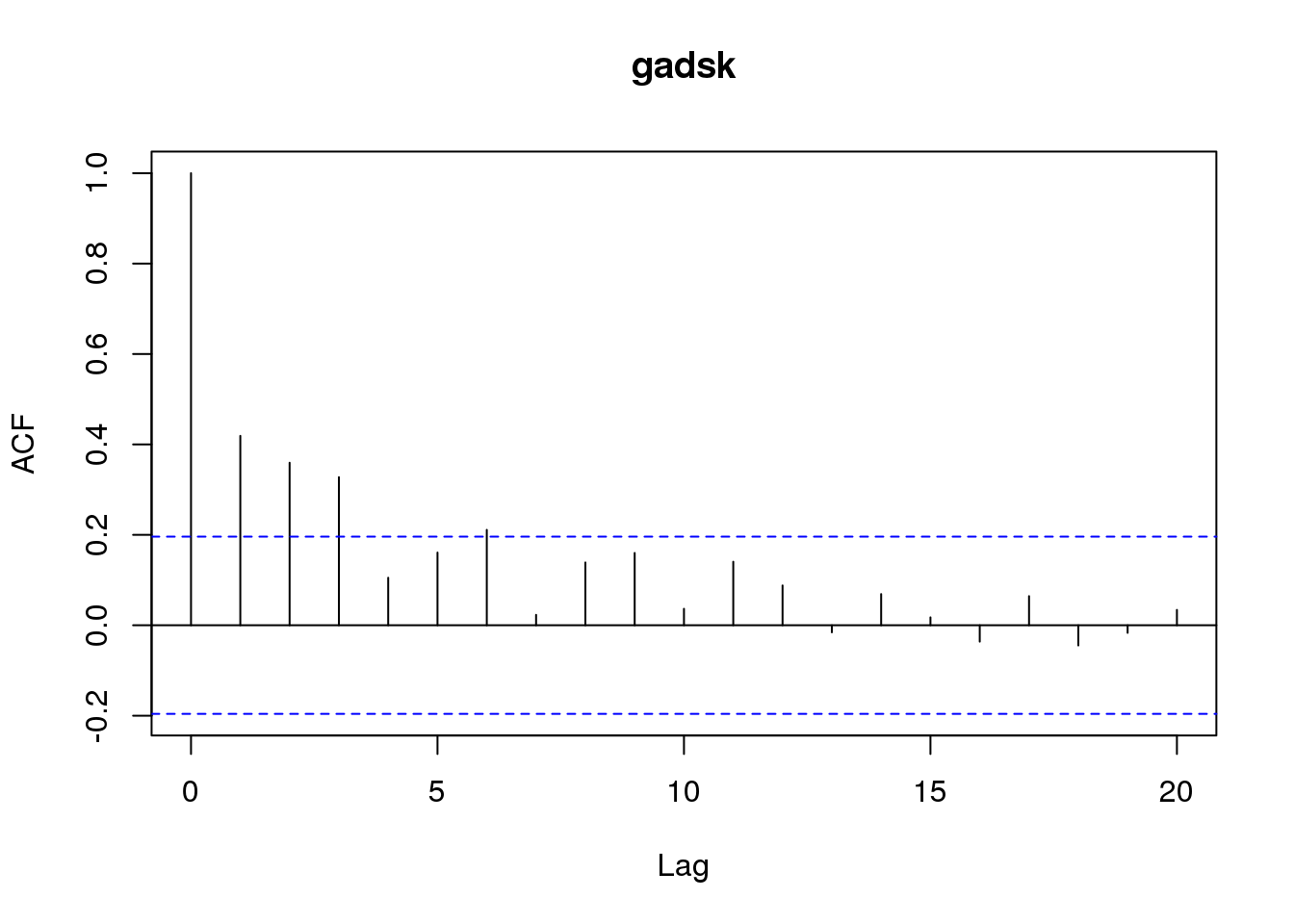
Figure 9.3: Priežu gadskārtu platumu aukorelācijas attēls
Ja nepieciešams iegūt autokorelācijas skaitliskās vērtības, tad funkcijas acf() rezultāts jāsaglabā kā objekts, kuru pēc tam apskatot var iegūt konkrētās vērtības.
akor<-acf(priede,plot=FALSE)
akor##
## Autocorrelations of series 'priede', by lag
##
## 0 1 2 3 4 5 6 7 8 9
## 1.000 0.419 0.360 0.328 0.105 0.161 0.211 0.023 0.139 0.160
## 10 11 12 13 14 15 16 17 18 19
## 0.036 0.141 0.088 -0.016 0.069 0.017 -0.036 0.064 -0.045 -0.017
## 20
## 0.034